The Silent Killer of AI Analytics: Almost Correct Is Still Wrong
AI is changing how companies make decisions. But beneath the excitement lies a quiet risk: even the smartest systems can misread data, misinterpret logic, and make confident but costly mistakes.
Every business leader experimenting with AI for analytics eventually faces the same question:
Can I trust the answer?
Generative AI can sound incredibly sure of itself while being dangerously mistaken, the ultimate confident liar. Asking ChatGPT to analyze your business data is like asking a brilliant, fast-talking intern to run your quarterly financials. They are smart and enthusiastic, but they lack the real-world context that separates a plausible answer from the right one.
That context gap is the biggest reason AI analytics fails in practice. At Alkemi, we decided to tackle the problem the same way cybersecurity experts test systems for weakness, by trying to break our own product.
The Silent Killer: "Almost Correct" SQL
When you ask a text-to-SQL system a question, it translates your words into a query. Most of the time, it is mostly right.
But in data, “almost correct” is just another word for “wrong.”
These queries run without error and produce charts that look believable. Yet a tiny flaw can distort the result, leading to decisions based on data that is not quite true.
A recent study, ReFoRCE (Snowflake AI and UC San Diego), showed that even the most advanced models still struggle with the complexity of real-world business data. It is not a syntax problem, it is a context problem. Understanding what a company really means by “revenue,” “active users,” or “Europe” requires more than technical precision.
Like that smart intern, AI can be quick, confident, and completely off base.
Here are the three types of mistakes we see most often.
Class 1: Misinterpreting Critical Business Logic
These are the most damaging errors. The code runs perfectly, but the logic ignores the financial or operational realities that drive your business.
Example: Gross vs. Net Revenue — The Refund Blind Spot
- The leader asks: “What was our total sales revenue for Q2?”
- The AI writes:

The hidden flaw: The AI calculates gross revenue, not net. It adds every sale but ignores the refunds table. The result inflates success, potentially leading to overpaid commissions and misleading board reports.
Example: The Currency Mix-Up
- The leader asks: "What was our total revenue from European sales in Q2?”
- The AI writes:
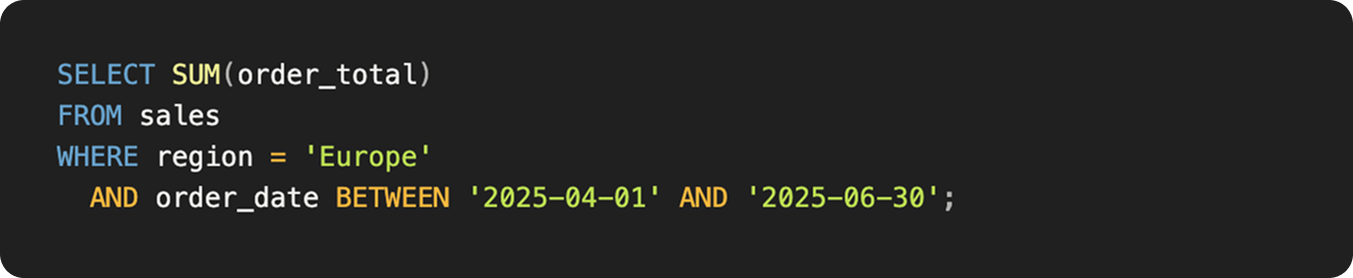
The hidden flaw: The column order_total is stored in local currencies. The AI adds euros, pounds, and francs together as if they were the same. The number looks solid but means nothing.
Takeaway: Even valid SQL can be wrong if the AI does not understand your business rules.
Class 2: Subtle Logical Flaws
These errors hide in plain sight. The logic looks sound, but the results are quietly skewed.
Example: Invisible Churn — Inner Join vs. Left Join
- The leader asks: "Show customers who have not purchased in the last six months.”
- The AI writes:

The hidden flaw:
- Active customers are included because the query does not exclude those with recent purchases.
- Customers who never purchased are excluded entirely because of the inner join.
Like an intern misfiling a report, the AI delivers a list that looks right but misses your actual target audience.
Example: The Phantom Market — The Missing Parentheses
- The leader asks: "What was our Q2 revenue for ‘Pro Series’ and ‘Elite Hardware’ in Texas?”
- The AI writes:
.png)
The hidden flaw: Because SQL processes AND before OR, the query pulls Texas revenue for Elite Hardware but global revenue for Pro Series. It looks like Texas is thriving when the numbers are global.
Takeaway: Small logic slips can lead to expensive strategic missteps.
Class 3: Answering the Wrong Question
Sometimes AI gets every calculation right but answers the wrong question entirely.
Example: The Forgotten Timeframe
- The leader asks: "Show me our top 10 customers this quarter.”
- The AI writes:
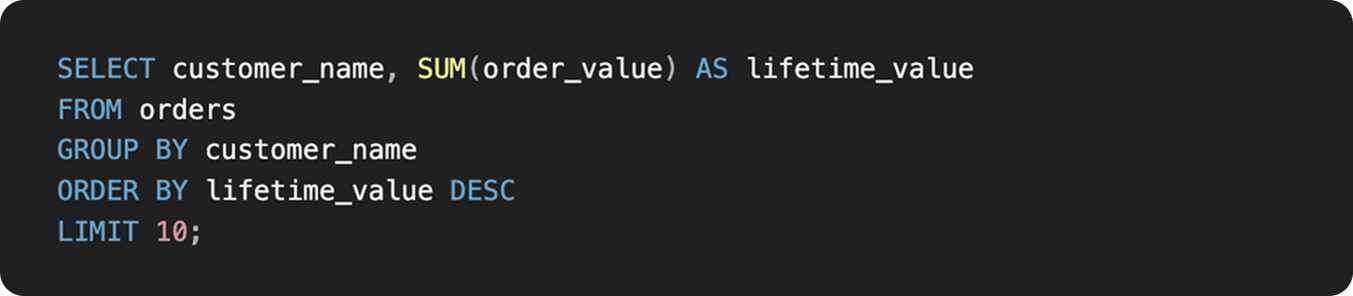
The hidden flaw: The query ignores “this quarter.” It returns all-time top customers, some of whom may have churned long ago.
Example: The Factually Useless Answer
- The leader asks: "On which date did we see the biggest day-over-day increase in signups last month?”
- The AI writes:

The hidden flaw: Everything works until the end. The query returns today’s date instead of the signup_date of the spike, losing the point of the question.
Takeaway: Without context, even correct math can answer the wrong problem.
Breaking Things on Purpose: Our AI "Red Team"
Most systems wait for you to notice their mistakes, if you ever do. Alkemi’s approach is different. We build AIs that try to break our own.
Inspired by cybersecurity’s “red teams,” we created an internal testing system that constantly challenges our models to find weak spots before they reach production.
How it works:
- The Breaker AI — Has full access to the data schema and context. Its job is to confuse our SQL generator, tricking it into writing flawed or “almost correct” queries.
- The Rater AI — Reviews every query and assigns a Certainty Score with a short explanation of potential issues.
- The Corrector AI — Steps in when confidence is low. It analyzes the flawed query, writes a corrected version, and adds the improvement to the training data so the same mistake will not happen again.
This process teaches the system to recognize and correct its own blind spots.

Taking Trust Further: Human-in-the-Loop
Automation gets you far, but trust requires transparency. Alkemi keeps humans in the loop, giving analysts and data owners visibility into what the AI is not sure about.
In the Text-to-SQL Training Hub, users can review uncertain queries, see suggested fixes in plain English, and approve or reject them with a single click. Each action strengthens the model with your business logic, turning expertise into scalable accuracy.
The Result: An AI You Can Actually Trust
By embracing a culture of breaking things on purpose, we have built a system that earns trust, query by query.
- Our AI Red Team proactively finds and fixes the “almost correct” errors that plague other systems.
- The Training Hub lets you apply your own business logic to the AI’s work.
- The Certainty Score gives you a transparent, real-time measure of confidence.
When your AI can admit it is wrong and learn from it, you gain something more powerful than automation: clarity, context, and confidence in every decision.
